LLM Integration Layer
Purpose and Scope
The LLM Integration Layer provides a unified, model-agnostic abstraction for interacting with multiple Large Language Model providers. This layer enables the Agentic Browser to seamlessly switch between different LLM providers (Google Gemini, OpenAI, Anthropic Claude, Ollama, Deepseek, OpenRouter) without modifying application code. It wraps LangChain chat model adapters and manages provider-specific configuration, API key handling, and parameter mapping.
This document covers the LargeLanguageModel class and the PROVIDER_CONFIGS registry. For environment variable configuration details, see Configuration and Environment Variables. For usage within agent systems, see React Agent Architecture and Browser Use Agent.
Sources: core/llm.py1-215
Architecture Overview
The LLM Integration Layer implements a provider abstraction pattern that decouples application logic from LLM provider implementations. The architecture consists of three key components:
- Provider Configuration Registry (
PROVIDER_CONFIGS): A dictionary mapping provider names to their LangChain adapter classes, API key requirements, default models, and parameter mappings - Abstraction Class (
LargeLanguageModel): A wrapper that instantiates the appropriate LangChain chat model based on provider selection - LangChain Adapters: Provider-specific chat model implementations (
ChatGoogleGenerativeAI,ChatOpenAI,ChatAnthropic,ChatOllama)
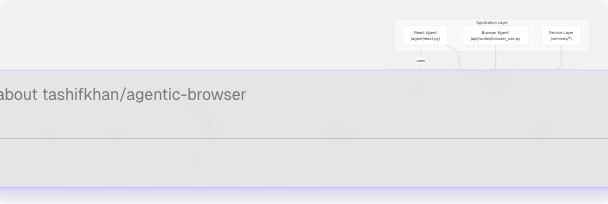
Sources: core/llm.py1-215
Provider Configuration System
The PROVIDER_CONFIGS dictionary serves as the central registry for all supported LLM providers. Each provider entry defines the LangChain adapter class, API key environment variable, default model, and parameter name mappings.
PROVIDER_CONFIGS Structure
| Field | Type | Description |
|---|---|---|
class |
Type[BaseChatModel] |
LangChain chat model class to instantiate |
api_key_env |
`str | None` |
base_url_env |
`str | None` |
base_url_override |
`str | None` |
default_model |
str |
Default model identifier |
param_map |
dict[str, str] |
Mapping from standard parameter names to provider-specific names |
Supported Providers

Google Provider
"google": {
"class": ChatGoogleGenerativeAI,
"api_key_env": "GOOGLE_API_KEY",
"default_model": "gemini-2.5-flash",
"param_map": {"api_key": "google_api_key"},
}
Uses the native Google Gemini adapter with parameter name google_api_key.
Sources: core/llm.py22-27
OpenAI Provider
"openai": {
"class": ChatOpenAI,
"api_key_env": "OPENAI_API_KEY",
"default_model": "gpt-5-mini",
"param_map": {
"api_key": "openai_api_key",
"base_url": "base_url",
},
}
Standard OpenAI implementation supporting custom base URLs.
Sources: core/llm.py28-36
Anthropic Provider
"anthropic": {
"class": ChatAnthropic,
"api_key_env": "ANTHROPIC_API_KEY",
"default_model": "claude-4-sonnet",
"param_map": {
"api_key": "anthropic_api_key",
"base_url": "base_url",
},
}
Anthropic Claude integration with support for custom endpoints.
Sources: core/llm.py37-45
Ollama Provider
"ollama": {
"class": ChatOllama,
"api_key_env": None,
"base_url_env": "OLLAMA_BASE_URL",
"default_model": "llama3",
"param_map": {
"base_url": "base_url",
},
}
Local Ollama deployment support. No API key required; only base URL configuration needed.
Sources: core/llm.py46-54
Deepseek Provider
"deepseek": {
"class": ChatOpenAI,
"api_key_env": "DEEPSEEK_API_KEY",
"base_url_override": "https://api.deepseek.com/v1",
"default_model": "deepseek-chat",
"param_map": {
"api_key": "openai_api_key",
"base_url": "base_url",
},
}
Leverages OpenAI API compatibility by reusing ChatOpenAI adapter with hardcoded base URL override.
Sources: core/llm.py55-64
OpenRouter Provider
"openrouter": {
"class": ChatOpenAI,
"api_key_env": "OPENROUTER_API_KEY",
"base_url_override": "https://openrouter.ai/api/v1",
"default_model": "mistralai/mistral-7b-instruct",
"param_map": {
"api_key": "openai_api_key",
"base_url": "base_url",
},
}
OpenRouter gateway supporting multiple models through OpenAI-compatible API.
Sources: core/llm.py65-74
LargeLanguageModel Class
The LargeLanguageModel class is the primary interface for LLM interactions. It handles provider selection, configuration resolution, credential management, and client instantiation.
Class Signature
class LargeLanguageModel:
def __init__(
self,
model_name: str | None = "gemini-2.5-flash",
api_key: str = google_api_key,
provider: Literal[
"google",
"openai",
"anthropic",
"ollama",
"deepseek",
"openrouter",
] = "google",
base_url: str | None = None,
temperature: float = 0.4,
**kwargs: Any,
):
# Implementation details...
Sources: core/llm.py78-94
Initialization Parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
model_name |
`str | None` | "gemini-2.5-flash" |
api_key |
str |
google_api_key |
API key (can be overridden by environment variable) |
provider |
Literal[...] |
"google" |
Provider selection from supported list |
base_url |
`str | None` | None |
temperature |
float |
0.4 |
Sampling temperature for generation |
**kwargs |
Any |
- | Additional provider-specific parameters |
Initialization Flow
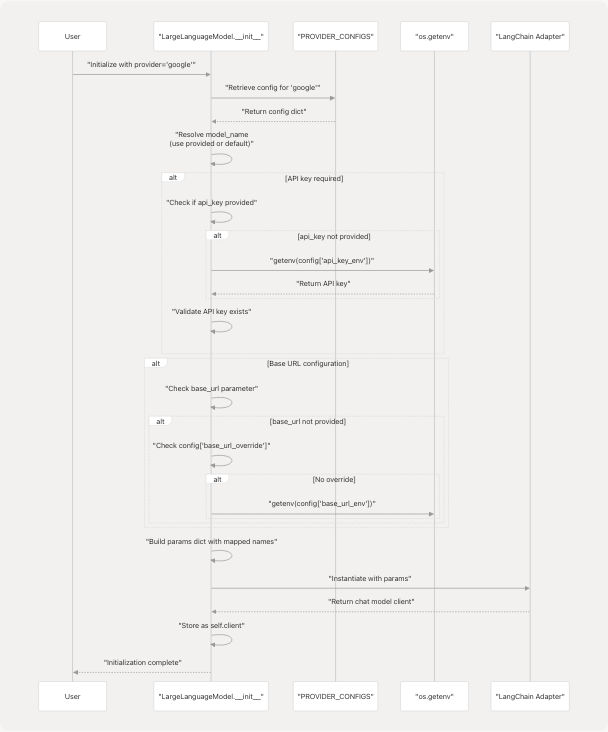
Sources: core/llm.py95-169
Configuration Resolution Logic
The initialization process follows this precedence order:
- Provider Validation: Checks if
providerexists inPROVIDER_CONFIGScore/llm.py98-105 - Model Name Resolution: Uses provided
model_nameor falls back toconfig["default_model"]core/llm.py108-113 - API Key Resolution:
- Uses provided
api_keyparameter - Falls back to environment variable specified in
config["api_key_env"] - Raises
ValueErrorif required but not found core/llm.py121-129
- Uses provided
- Base URL Resolution:
- Uses provided
base_urlparameter - Falls back to
config["base_url_override"](hardcoded) - Falls back to environment variable from
config["base_url_env"] - Raises
ValueErrorif required but not found core/llm.py136-155
- Uses provided
- Parameter Mapping: Maps generic parameter names to provider-specific names using
config["param_map"]core/llm.py128-149
Sources: core/llm.py95-169
Methods
generate_text()
Primary method for text generation with optional system message support.
def generate_text(
self,
prompt: str,
system_message: str | None = None,
) -> str:
messages: list[BaseMessage] = []
if system_message:
messages.append(SystemMessage(content=system_message))
messages.append(HumanMessage(content=prompt))
try:
response = self.client.invoke(messages)
return str(response.content)
except Exception as e:
raise RuntimeError(
f"Error generating text with {self.provider} ({self.model_name}): {e}"
)
Parameters:
prompt(str): User message to send to the LLMsystem_message(str | None): Optional system prompt for context
Returns: Generated text content as string
Raises: RuntimeError if generation fails
Sources: core/llm.py171-190
summarize_text()
Placeholder method for text summarization (currently returns truncated text).
def summarize_text(self, text: str) -> str:
return f"Summary of the text: {text[:50]}..."
Sources: core/llm.py192-193
Default LLM Instance
The module provides a pre-initialized default LLM instance for convenience:
# Initialize default LLM instance for application use
try:
_model = LargeLanguageModel()
llm = _model.client
except Exception as e:
print(f"Failed to initialize default LLM: {e}")
raise e
This creates:
_model: CompleteLargeLanguageModelwrapper instancellm: Direct reference to the underlying LangChain chat model client
The default instance uses:
- Provider:
"google" - Model:
"gemini-2.5-flash" - API Key: From
google_api_key(imported fromcore.config) - Temperature:
0.4
This llm client is imported by various modules for direct LangChain integration, particularly in agent tools and services.
Sources: core/llm.py197-205
Parameter Mapping System
The param_map dictionary in each provider config translates generic parameter names to provider-specific parameter names. This abstraction allows the LargeLanguageModel class to use consistent naming while adapting to different LangChain adapter APIs.
Common Mappings
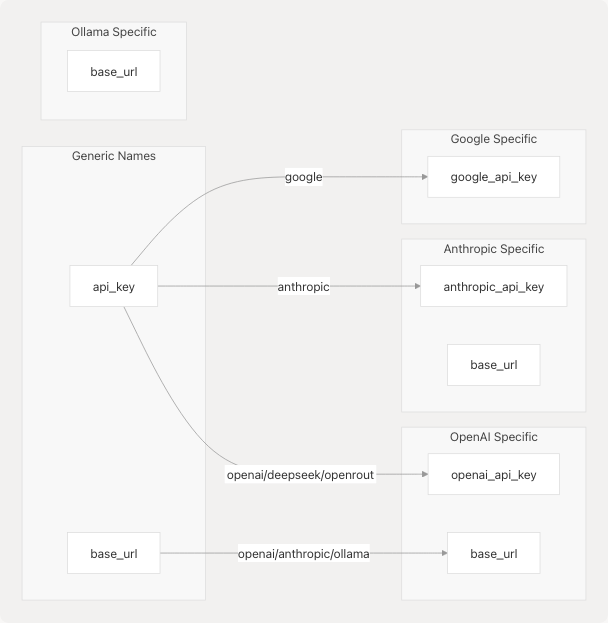
Example: OpenAI-Compatible Providers
Both Deepseek and OpenRouter reuse the ChatOpenAI adapter class but map to different base URLs:
# Deepseek configuration
"deepseek": {
"class": ChatOpenAI, # Reuse OpenAI adapter
"base_url_override": "https://api.deepseek.com/v1",
"param_map": {
"api_key": "openai_api_key", # Maps to openai_api_key parameter
"base_url": "base_url",
},
}
# OpenRouter configuration
"openrouter": {
"class": ChatOpenAI, # Reuse OpenAI adapter
"base_url_override": "https://openrouter.ai/api/v1",
"param_map": {
"api_key": "openai_api_key",
"base_url": "base_url",
},
}
This demonstrates the extensibility of the system: any OpenAI-compatible API can be integrated by adding a new provider config with a base_url_override.
Sources: core/llm.py55-74
Usage Patterns
Basic Instantiation
from core.llm import LargeLanguageModel
# Use default Google Gemini
llm = LargeLanguageModel()
# Specify provider and model
llm = LargeLanguageModel(
provider="anthropic",
model_name="claude-4-sonnet",
temperature=0.7
)
# Use local Ollama
llm = LargeLanguageModel(
provider="ollama",
model_name="llama3",
base_url="http://localhost:11434"
)
Integration with LangChain
The .client attribute exposes the underlying LangChain BaseChatModel for direct use in LangChain workflows:
from core.llm import LargeLanguageModel
from langchain_core.messages import HumanMessage
llm = LargeLanguageModel(provider="openai", model_name="gpt-4")
messages = [HumanMessage(content="Explain quantum computing")]
response = llm.client.invoke(messages)
Usage in React Agent
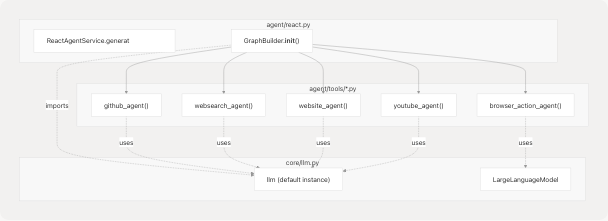
Agent tools import the default llm instance directly:
from core.llm import llm
@tool
def github_agent(repo_url: str, question: str) -> str:
# ... code ...
result = llm.invoke(messages)
# ... code ...
Sources: core/llm.py197-205
Usage in Browser Use Agent
The Browser Use Agent creates custom instances for script generation:
from core.llm import LargeLanguageModel
async def generate_script(request: GenerateScriptRequest):
llm = LargeLanguageModel(
model_name=request.model_name or "gemini-2.0-flash-exp",
provider="google",
temperature=0.3,
)
response = llm.generate_text(
prompt=script_generation_prompt,
system_message=system_instructions
)
Sources: core/llm.py78-190
Error Handling
The LargeLanguageModel class implements comprehensive error handling at multiple stages:
Initialization Errors
| Error Type | Trigger Condition | Error Message Pattern |
|---|---|---|
ValueError |
Invalid provider name | "Unsupported LLM provider: '{provider}'. Please choose from..." |
ValueError |
No model name provided or found | "No model_name provided and no default_model set for '{provider}'." |
ValueError |
Required API key missing | "API key for '{provider}' not found. Please provide it directly or set the '{env_var}' environment variable." |
ValueError |
Required base URL missing | "Base URL for '{provider}' not found. Please provide it directly or set the '{env_var}' environment variable." |
RuntimeError |
LangChain adapter instantiation fails | "Failed to initialize LLM for '{provider}' with model '{model_name}'. Details: {e}..." |
Sources: core/llm.py101-169
Runtime Errors
def generate_text(self, prompt: str, system_message: str | None = None) -> str:
try:
response = self.client.invoke(messages)
return str(response.content)
except Exception as e:
raise RuntimeError(
f"Error generating text with {self.provider} ({self.model_name}): {e}"
)
All generation errors are wrapped in RuntimeError with context about the provider and model being used.
Sources: core/llm.py183-190
Configuration Dependencies
The LLM Integration Layer depends on environment variables and configuration from core.config:
from .config import google_api_key
The module imports google_api_key which is read from the GOOGLE_API_KEY environment variable in the config module. This serves as the default API key when no explicit key is provided.
For detailed environment variable configuration, see Configuration and Environment Variables.
Sources: core/llm.py2 core/__init__.py1-15
Extension Points
Adding New Providers
To add support for a new LLM provider:
-
Add LangChain adapter dependency to
pyproject.toml -
Import adapter class in
core/llm.py -
Register in PROVIDER_CONFIGS:
"new_provider": { "class": ChatNewProvider, "api_key_env": "NEW_PROVIDER_API_KEY", "default_model": "model-name", "param_map": { "api_key": "provider_specific_key_param", }, }
-
Update type hints in
providerparameter Literal type -
Add environment variable to
.env.example
OpenAI-Compatible API Integration
For APIs following OpenAI specifications (like Deepseek, OpenRouter):
"custom_provider": {
"class": ChatOpenAI, # Reuse OpenAI adapter
"api_key_env": "CUSTOM_API_KEY",
"base_url_override": "https://api.custom-provider.com/v1",
"default_model": "custom-model-name",
"param_map": {
"api_key": "openai_api_key",
"base_url": "base_url",
},
}
Sources: core/llm.py21-75
Testing and Validation
The module includes a __main__ block for basic testing:
if __name__ == "__main__":
llm = LargeLanguageModel(
model_name="gemini-2.5-flash",
provider="google",
temperature=0.3,
)
response = llm.generate_text("Hello, how are you?")
print(response)
This validates:
- Provider initialization
- Configuration resolution
- Basic text generation
- Response handling
Sources: core/llm.py207-214
Key Design Principles
- Provider Agnosticism: Application code remains independent of LLM provider implementation details
- Configuration-Driven: All provider-specific logic is data-driven through
PROVIDER_CONFIGS - Graceful Degradation: Clear error messages guide users to fix configuration issues
- LangChain Integration: Seamless compatibility with LangChain's ecosystem
- Extensibility: New providers can be added without modifying core logic
- Type Safety: Type hints and Literal types prevent invalid provider selection at development time
- Credential Management: Secure handling of API keys through environment variables with fallback support
Sources: core/llm.py1-215