Hiring Assistant Service
Purpose and Scope
The Hiring Assistant Service generates role-specific answers to interview questions, leveraging resume context and company research to provide personalized, relevant responses. This service helps job seekers prepare for interviews by analyzing their background against the target role and company, producing tailored answers within specified word limits.
This document covers the interview answer generation service. For resume analysis capabilities, see Resume Analysis Service. For cold email generation that also uses company research, see Cold Mail Generator Service. For the web search and content extraction agents used by this service, see Support Agents.
Sources: backend/app/models/schemas.py204-238 Diagram 2 (Backend AI/ML Service Architecture)
Service Architecture Overview
The Hiring Assistant Service follows a three-stage pipeline: request validation, company research enrichment, and LLM-powered answer generation. The service integrates with external research agents to gather company context and uses Google Gemini for natural language generation.
Sources: backend/app/services/cold_mail.py7 backend/app/core/llm.py1-37 backend/app/agents/__init__.py1-13 Diagram 2 (Backend AI/ML Service Architecture)
Request and Response Models
HiringAssistantRequest
The service accepts structured interview preparation requests with role context, questions, and company information.
| Field | Type | Required | Default | Description |
|---|---|---|---|---|
role |
str |
Yes | - | Target role (e.g., "Software Engineer") |
questions |
List[str] |
No | [] |
List of interview questions to answer |
company_name |
str |
Yes | - | Target company name |
user_knowledge |
Optional[str] |
No | "" |
Candidate's existing knowledge about company/role |
company_url |
Optional[str] |
No | None |
Company website URL for research |
word_limit |
Optional[int] |
No | 150 |
Word limit per answer (50-500 range) |
Validation Rules:
role: Minimum length 1 character backend/app/models/schemas.py205-208company_name: Minimum length 1 character backend/app/models/schemas.py214-217word_limit: Range validated between 50 and 500 words backend/app/models/schemas.py227-232
HiringAssistantResponse
The service returns a structured response mapping each question to its generated answer.
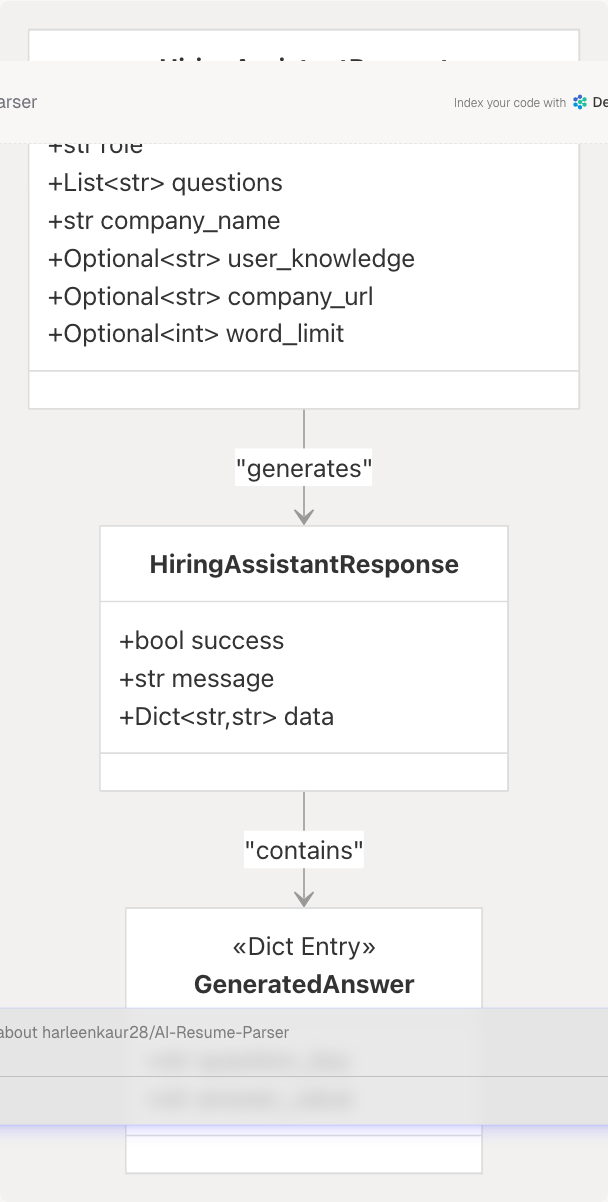
Response Structure:
success: Boolean indicating operation success (default:True) backend/app/models/schemas.py236message: Human-readable status message (default: "Answers generated successfully.") backend/app/models/schemas.py237data: Dictionary mapping questions to answers backend/app/models/schemas.py238
Sources: backend/app/models/schemas.py204-238
Company Research Integration
The Hiring Assistant Service enriches answer generation with company-specific context through the get_company_research() function. This function is imported from app.services.hiring_assiatnat and provides contextual information about the target company.
Research Flow
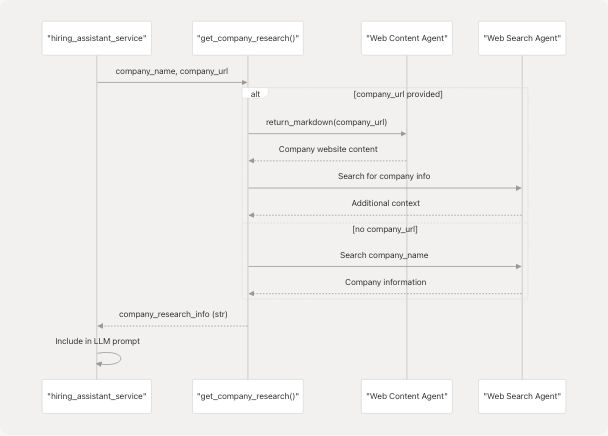
Research Usage Pattern
The service conditionally fetches company research based on the presence of company_url:
# Pattern from cold_mail.py that hiring assistant follows
company_research_info = ""
if company_url:
company_research_info = get_company_research(company_name, company_url)
This pattern is consistent across services that require company context, including the Cold Mail Generator backend/app/services/cold_mail.py308-311
Sources: backend/app/services/cold_mail.py7-311 backend/app/agents/__init__.py7 Diagram 2 (Backend AI/ML Service Architecture)
Answer Generation Process
The Hiring Assistant Service uses a multi-stage process to generate contextual, role-specific interview answers.
Generation Pipeline
Prompt Context Structure
The service constructs a comprehensive prompt context that includes:
- Role Information: Target position and responsibilities
- Questions List: Interview questions to be answered
- Company Context: Research findings about the company
- User Knowledge: Candidate's existing understanding
- Resume Context: Implicit from session/request (passed separately)
- Word Limit: Constraint for each answer
LLM Configuration
The service uses the shared Google Gemini LLM instance:
- Model:
gemini-2.0-flashbackend/app/core/llm.py7 - Temperature:
0.1(low variability for consistent answers) backend/app/core/llm.py22 - Provider: Google Generative AI via LangChain backend/app/core/llm.py1
Sources: backend/app/core/llm.py1-37 backend/app/models/schemas.py204-232 Diagram 2 (Backend AI/ML Service Architecture)
Answer Quality Features
The Hiring Assistant Service incorporates several features to ensure high-quality, relevant answers:
Word Limit Enforcement
Answers are constrained by the word_limit parameter with validation:
- Minimum: 50 words
- Maximum: 500 words
- Default: 150 words
This ensures answers are concise yet comprehensive enough for interview preparation.
Contextual Relevance
Answers incorporate multiple context layers:
| Context Type | Source | Purpose |
|---|---|---|
| Role-specific | role field |
Tailor answers to position requirements |
| Company-specific | company_research_info |
Align with company culture/values |
| Candidate knowledge | user_knowledge field |
Build on existing understanding |
| Resume data | Session context | Reference actual experience |
Multi-Question Support
The service processes multiple questions in a single request, maintaining consistency across answers while providing question-specific responses. The response data field maps each question to its corresponding answer backend/app/models/schemas.py238
Sources: backend/app/models/schemas.py227-232 Diagram 4 (Data Flow for Resume Analysis)
Integration Points
Frontend Integration
The Hiring Assistant Service is accessed from the dashboard interface at /dashboard/hiring-assistant:
The frontend pre-populates resume context from localStorage, which is set during resume analysis backend/app/models/schemas.py173 This enables seamless transition from resume analysis to interview preparation.
Backend Service Dependencies
The service relies on several backend components:
- LLM Core: Shared Google Gemini instance backend/app/core/llm.py6-28
- Web Content Agent: Markdown extraction via Jina AI backend/app/agents/__init__.py7
- Web Search Agent: Company research via Tavily backend/app/agents/__init__.py5
- Company Research Function:
get_company_research()fromapp.services.hiring_assiatnat
Cross-Service Integration
The Hiring Assistant shares infrastructure with other AI services:
Both the Hiring Assistant and Cold Mail Generator use the same company research function backend/app/services/cold_mail.py7-311 demonstrating shared service patterns across the backend.
Sources: backend/app/services/cold_mail.py7-311 backend/app/core/llm.py1-37 backend/app/agents/__init__.py1-13 Diagram 3 (Frontend Application Architecture), Diagram 4 (Data Flow for Resume Analysis)
Error Handling and Validation
The service implements comprehensive validation and error handling:
Request Validation
Validation is enforced through Pydantic models backend/app/models/schemas.py204-232:
- Field Constraints: Minimum lengths and range validation
- Type Checking: Strict type enforcement for all fields
- Default Values: Sensible defaults for optional parameters
Common Error Scenarios
| Error Type | Status Code | Trigger Condition |
|---|---|---|
| Validation Error | 400 | Missing required fields or invalid types |
| Service Unavailable | 503 | LLM service not initialized |
| Processing Error | 500 | Company research failure or LLM timeout |
| Invalid Word Limit | 400 | word_limit outside 50-500 range |
LLM Service Availability Check
Following the pattern from related services, the Hiring Assistant checks LLM availability:
# Pattern from cold_mail.py
if not llm:
raise HTTPException(
status_code=503,
detail=ErrorResponse(
message="LLM service is not available."
).model_dump(),
)
This check occurs at the service entry point before processing the request backend/app/services/cold_mail.py255-258
Sources: backend/app/models/schemas.py204-238 backend/app/services/cold_mail.py255-258 backend/app/core/llm.py6-17
Usage Workflow
The typical usage workflow for the Hiring Assistant Service:
Sources: backend/app/models/schemas.py204-238 backend/app/services/cold_mail.py308-311 Diagram 3 (Frontend Application Architecture), Diagram 4 (Data Flow for Resume Analysis)
Performance Considerations
Processing Time
The service processing time is influenced by:
- Company Research (0-2 seconds): Optional, depends on
company_urlpresence - LLM Generation (2-5 seconds per question): Varies with number of questions and word limit
- Total Latency: Approximately 2-10 seconds for typical requests
Optimization Strategies
The service can leverage several optimization techniques:
- Batch Processing: Multiple questions processed in single LLM call
- Research Caching: Company research results can be cached for repeated requests
- Word Limit Tuning: Lower word limits reduce LLM generation time
- Faster Model: Could use
gemini-2.0-flash-litebackend/app/core/llm.py10 for improved speed with minimal quality tradeoff
Concurrent Request Handling
The FastAPI backend supports asynchronous processing, enabling efficient handling of multiple concurrent interview preparation requests. The service follows async patterns used by other AI services backend/app/services/cold_mail.py445
Sources: backend/app/core/llm.py7-28 backend/app/services/cold_mail.py445 Diagram 6 (Deployment & Infrastructure Architecture)