Resume Analysis Service
Purpose and Scope
The Resume Analysis Service is the foundational AI/ML service in TalentSync that processes uploaded resume files and extracts structured, actionable data. This service combines traditional machine learning with modern large language models to perform multi-stage analysis: text extraction from various file formats, NLP-based cleaning, category classification using TF-IDF and scikit-learn, and deep semantic extraction using Google Gemini 2.0 Flash.
This document covers the core resume parsing and analysis functionality. For information about:
- ATS evaluation against job descriptions, see ATS Evaluation Service
- Resume tailoring and optimization, see Tailored Resume Service
- Tips generation for resume improvement, see the tips generation endpoints in Resume Analysis Service
High-Level Architecture
The Resume Analysis Service follows a multi-stage pipeline architecture where each stage adds progressively richer information:
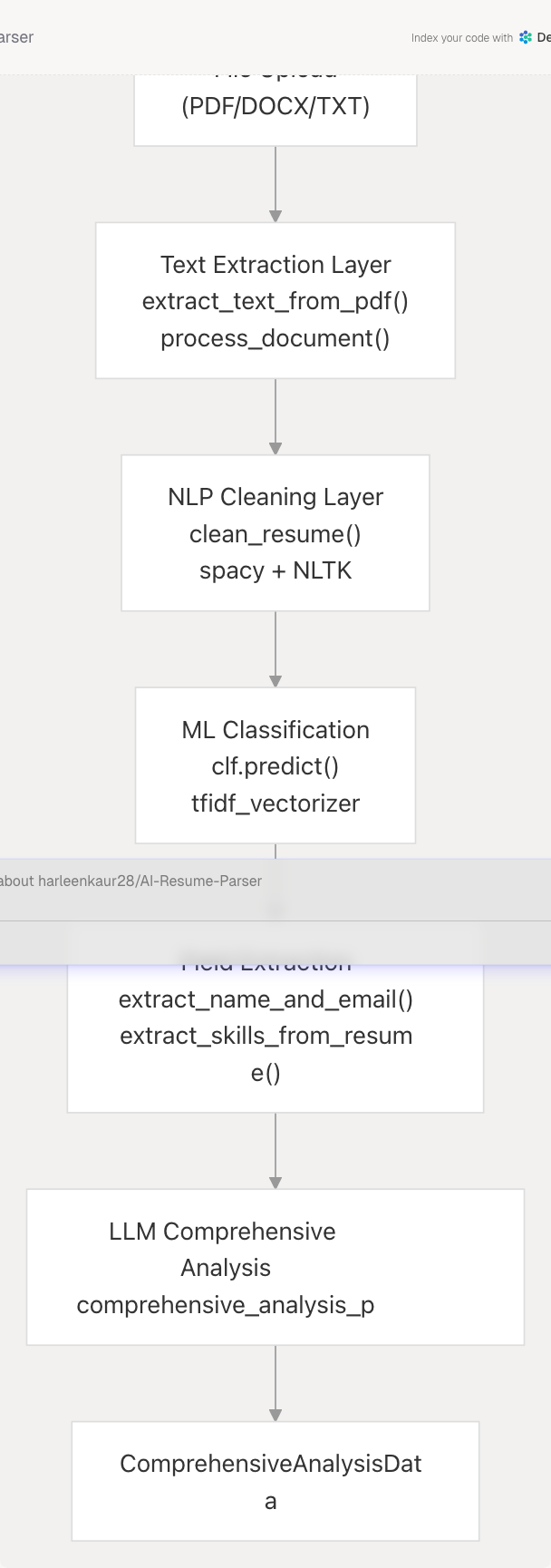
Sources: backend/server.py1-1100
Service Entry Points
The Resume Analysis Service exposes its functionality through FastAPI endpoints defined in the main server module:
| Endpoint | Method | Purpose | Response Model |
|---|---|---|---|
/analyze_resume |
POST | Full resume analysis pipeline | ComprehensiveAnalysisResponse |
/tips |
GET | Generate resume and interview tips | TipsResponse |
/format |
POST | Clean and format resume text | JSON with cleaned_text and analysis |
Sources: backend/server.py52-66
Text Extraction and Processing
File Format Support
The service supports three primary file formats through dedicated extraction functions:
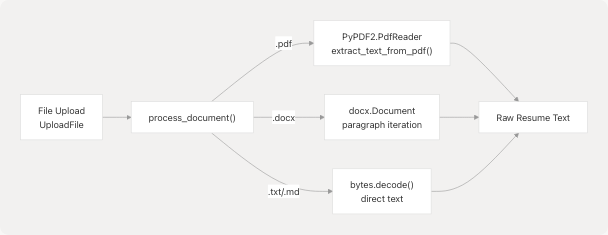
Implementation Details:
The process_document() function at backend/server.py764-793 handles file type detection and routing:
- PDF files: Uses
PyPDF2.PdfReaderto extract text from all pages iteratively - DOCX files: Uses
python-docxlibrary to extract text from paragraphs - TXT/MD files: Direct UTF-8 decoding of bytes
The extract_text_from_pdf() helper at backend/server.py752-762 specifically handles PDF extraction with error handling for corrupted or protected files.
Sources: backend/server.py752-793
NLP Cleaning Pipeline
Text Normalization Process
The clean_resume() function at backend/server.py738-750 implements a comprehensive NLP cleaning pipeline:
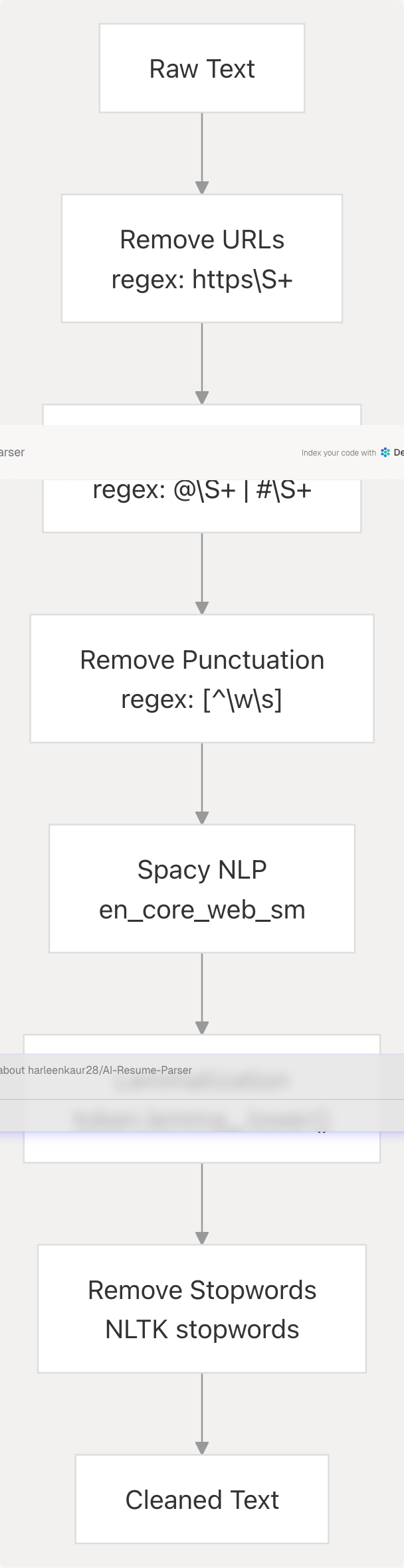
Implementation:
- URL and Social Media Removal backend/server.py740-742: Strips URLs, Twitter mentions, and hashtags using regex patterns
- Punctuation Removal backend/server.py742: Removes all non-word characters except whitespace
- Spacy Processing backend/server.py744: Creates a Doc object with tokenization and linguistic annotations
- Lemmatization backend/server.py745-746: Converts tokens to base forms (e.g., "running" → "run")
- Stopword Filtering backend/server.py745-746: Removes common English words using NLTK's stopwords corpus
The service initializes the Spacy model and NLTK data at startup backend/server.py702-711
Sources: backend/server.py660-711 backend/server.py738-750
ML Classification Pipeline
TF-IDF Vectorization and Scikit-Learn Classifier
The service uses a pre-trained machine learning pipeline for job category prediction:

Model Loading:
The service loads two pre-trained pickle files at initialization backend/server.py714-735:
tfidf.pkl: Trained TF-IDF vectorizer for text feature extractionbest_model.pkl: Trained classifier (likely RandomForest or similar) for 25 job categories
Classification Process:
The cleaned text is transformed into a TF-IDF feature vector and passed through the classifier to predict the most likely job category. This prediction is used to:
- Provide context to the LLM for comprehensive analysis
- Infer relevant skills if the resume is sparse
- Generate category-specific tips and recommendations
Categories: The classifier predicts from 25 distinct job categories including roles like "Java Developer", "Data Science", "HR", "Advocate", "Business Analyst", etc.
Sources: backend/server.py714-735
Field Extraction
Regex-Based Information Extraction
The service implements specialized extraction functions for structured resume fields:

Extraction Functions:
| Function | Purpose | Pattern/Strategy | Lines |
|---|---|---|---|
extract_name_and_email() |
Extract name (first line) and email | Email regex: [a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,} |
backend/server.py923-933 |
extract_contact_number_from_resume() |
Extract phone numbers | Phone pattern: \+?\d{1,3}[-.\s]?\(?\d{3}\)?[-.\s]?\d{3}[-.\s]?\d{4} |
backend/server.py936-944 |
extract_college_name() |
Extract institution name | Line matching: `college | university |
extract_education_info() |
Extract degree information | Pattern: `Bachelor | B.S. |
extract_work_experience() |
Extract work experience entries | Keywords: `intern | manager |
extract_projects() |
Extract project information | Section headers: `PROJECTS | PERSONAL PROJECTS |
The extract_projects() function uses a stateful parser that identifies project sections and extracts all text until the next major section header.
Sources: backend/server.py923-1026
Comprehensive Analysis with LLM
Google Gemini 2.0 Flash Integration
The service uses Google's Gemini 2.0 Flash model through LangChain for deep semantic analysis:
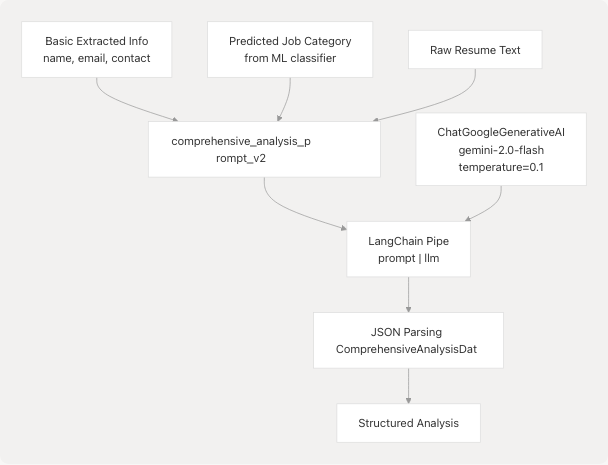
Prompt Engineering:
The service defines a detailed prompt template at backend/server.py373-453 that instructs the model to:
- Extract and structure information from raw resume text
- Infer the predicted field if not provided (primary professional domain)
- Populate structured data matching the
ComprehensiveAnalysisDataPydantic schema - Assign skill proficiency percentages (0-100) based on context and frequency
- Generate recommended roles (3-4 job titles aligned with skills)
- Extract languages with proficiency levels (or infer "English (Professional)")
- List education qualifications (or infer typical qualification)
- Detail work experience with role, company, duration, and bullet points
- Extract projects with title, technologies, and description
Inference Rules:
The prompt includes explicit instructions for handling sparse data backend/server.py427-449:
- If skills are minimal, infer 1-2 common skills for the predicted field and append "(inferred)"
- If languages are not mentioned, add "English (Professional) (inferred)"
- If education is absent, infer typical qualification for the field and mark "(inferred)"
- If projects are not mentioned, create 1-2 typical projects for the field and mark "(inferred)"
LLM Configuration:
The LLM is initialized at startup backend/server.py68-86 with:
- Model:
gemini-2.0-flash - Temperature:
0.1(low temperature for consistent, factual output) - API Key: Retrieved from
GOOGLE_API_KEYenvironment variable
Sources: backend/server.py68-86 backend/server.py373-463
Data Models
Pydantic Schemas
The service defines comprehensive Pydantic models for type-safe data handling:
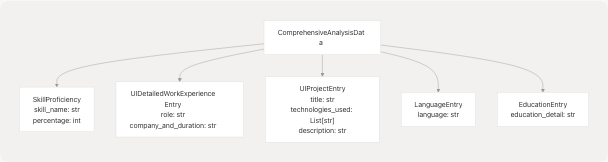
Core Models:
| Model | Purpose | Key Fields | Lines |
|---|---|---|---|
ComprehensiveAnalysisData |
Primary analysis output | skills_analysis, recommended_roles, languages, education, work_experience, projects, name, email, contact, predicted_field |
backend/server.py198-209 |
SkillProficiency |
Skill with proficiency level | skill_name: str, percentage: int |
backend/server.py173-176 |
UIDetailedWorkExperienceEntry |
Work experience entry | role: str, company_and_duration: str, bullet_points: List[str] |
backend/server.py178-182 |
UIProjectEntry |
Project details | title: str, technologies_used: List[str], description: str |
backend/server.py184-188 |
LanguageEntry |
Language proficiency | language: str (e.g., "English (Native)") |
backend/server.py190-192 |
EducationEntry |
Education qualification | education_detail: str (e.g., "B.Tech in ECE - XYZ University") |
backend/server.py194-196 |
Response Wrappers:
ComprehensiveAnalysisResponsebackend/server.py211-216: WrapsComprehensiveAnalysisDatawithsuccess,message, and optionalcleaned_textTipsDatabackend/server.py223-226: Containsresume_tipsandinterview_tipsas lists ofTipobjectsTipsResponsebackend/server.py228-232: WrapsTipsDatawith success status
Sources: backend/server.py173-232
Resume Formatting with LLM
Optional Text Cleanup Service
The service provides an optional LLM-based text formatting function to clean poorly extracted resume text:

Implementation:
The format_resume_text_with_llm() function at backend/server.py795-899 uses Google Gemini to:
- Remove formatting errors and inconsistent spacing
- Eliminate extraction artifacts (page numbers, headers/footers)
- Organize information logically under clear section headings
- Improve readability with consistent spacing and bullet points
- Preserve all substantive content
Prompt Template:
The formatting prompt backend/server.py843-867 instructs the model to:
- Preserve all key information (contact, summary, experience, education, skills, projects)
- Organize logically with section headings (Contact Info, Summary, Experience, etc.)
- Remove non-content artifacts
- Output plain text only (no markdown or commentary)
Error Handling:
The function includes comprehensive error handling backend/server.py880-899:
- Catches API authentication issues
- Handles rate limit errors
- Falls back to returning original text if LLM formatting fails
Sources: backend/server.py795-899
Tips Generation Service
Career Advice System
The service generates personalized resume and interview tips using LLM-based analysis:
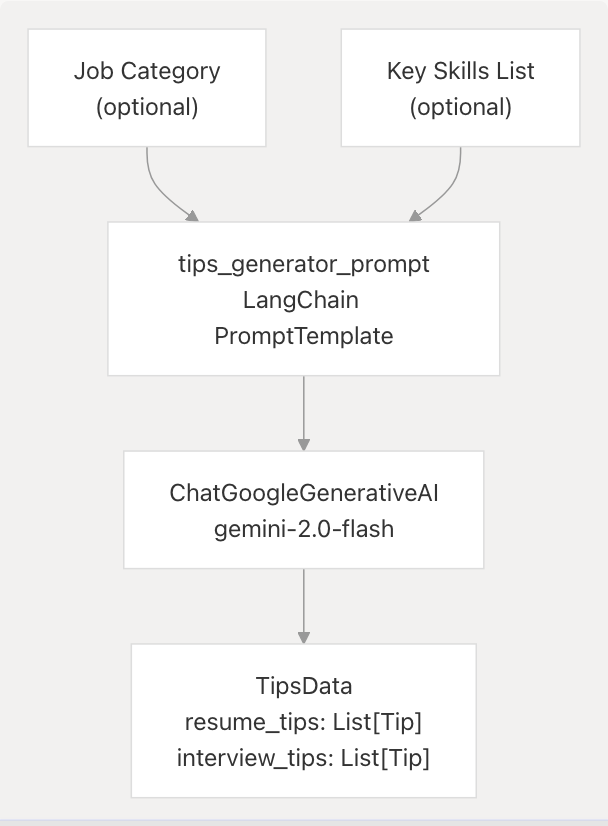
Tip Categories:
The system generates two types of tips:
-
Resume Tips backend/server.py473-474: 3-5 tips covering:
- Content improvements
- Keyword optimization
- Impact and metrics
- Formatting best practices
- Common mistakes to avoid
-
Interview Tips backend/server.py475-476: 3-5 tips covering:
- Pre-interview research
- STAR method for behavioral questions
- Question answering strategies
- Body language and communication
- Post-interview follow-up
Tip Structure:
Each tip is a Tip object backend/server.py218-221 with:
category: str: Classification (e.g., "Content", "Keywords", "Preparation")advice: str: Actionable guidance
Customization:
When job category or skills are provided, the system generates 1-2 tips specifically relevant to that domain.
Sources: backend/server.py218-232 backend/server.py465-500
Format and Analyze Service
Combined Formatting and Analysis Pipeline
The service provides a comprehensive endpoint that combines text formatting with analysis:
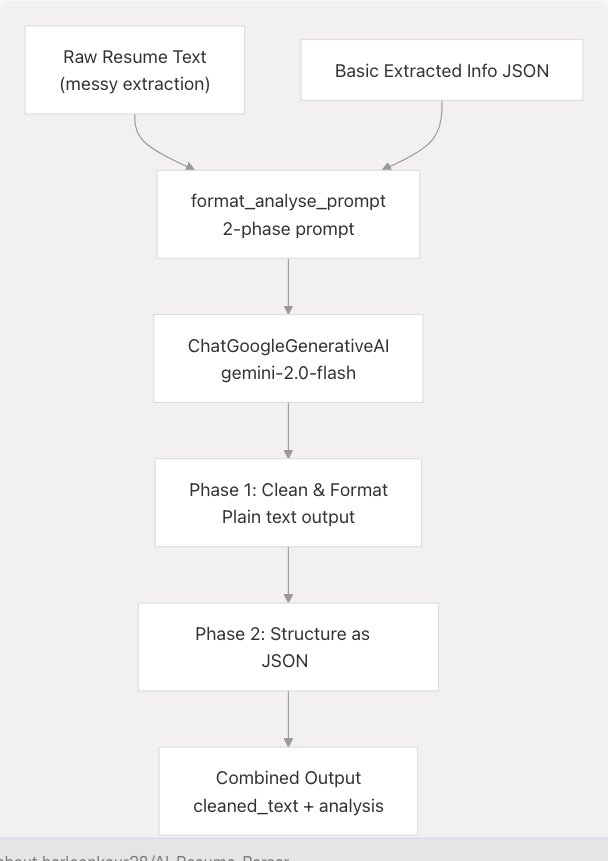
Two-Phase Prompt:
The format_analyse_prompt at backend/server.py503-602 implements a sophisticated two-phase instruction:
Phase 1 - Clean & Format backend/server.py506-521:
- Transform messy text into professional plain-text resume
- Preserve every substantive detail
- Re-organize logically under clear section headings
- Use consistent spacing and bullet points
- Remove extraction artifacts
Phase 2 - Structure as JSON backend/server.py522-593:
- Extract information from cleaned text
- Populate
ComprehensiveAnalysisDatafields - Infer predicted field (professional domain)
- Build skills analysis with proficiency percentages
- Suggest recommended roles
- Extract languages, education, work experience, projects
- Apply inference rules with "(inferred)" markers
Output Format:
Returns a single JSON object with two top-level keys:
{
"cleaned_text": "<full cleaned resume as plain text>",
"analysis": { ... }
}
Sources: backend/server.py503-602
Integration with Other Services
Service Dependencies
The Resume Analysis Service serves as a foundational component for other services:
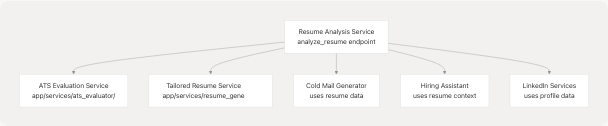
Downstream Consumers:
- ATS Evaluation Service backend/app/services/ats_evaluator/graph.py1-213: Uses resume text and predicted field to evaluate against job descriptions
- Tailored Resume Service backend/app/services/resume_generator/graph.py72-235: Leverages comprehensive analysis to optimize resumes for specific roles
- Cold Mail Generator: Uses structured resume data to personalize outreach emails
- Hiring Assistant: References resume context when generating interview answers
- LinkedIn Services: Utilizes profile information for content generation
Data Flow Pattern:
The typical flow is:
- User uploads resume → Resume Analysis Service generates
ComprehensiveAnalysisData - Frontend stores analysis in localStorage
- User navigates to downstream feature (ATS, Cold Mail, etc.)
- Downstream service consumes structured analysis data
Sources: backend/app/services/ats_evaluator/graph.py1-213 backend/app/services/resume_generator/graph.py1-240
External Dependencies
Third-Party Libraries and Models
The Resume Analysis Service relies on several external dependencies:
| Dependency | Version | Purpose | Configuration |
|---|---|---|---|
fastapi |
>=0.115.12 | API framework | backend/pyproject.toml10 |
pydantic |
~2.11.5 | Data validation | Implicit via FastAPI |
spacy |
3.8.7 | NLP processing | Model: en_core_web_sm |
nltk |
3.9.1 | Stopwords, tokenization | Data: stopwords corpus |
scikit-learn |
>=1.7.0 | ML classification | Pre-trained models |
PyPDF2 |
Implicit | PDF text extraction | Imported in server.py |
python-docx |
Implicit | DOCX text extraction | Imported as docx |
langchain |
>=0.3.25 | LLM orchestration | backend/pyproject.toml11 |
langchain-google-genai |
>=2.1.5 | Gemini integration | backend/pyproject.toml12 |
python-dotenv |
>=1.1.0 | Environment variables | backend/pyproject.toml14 |
Model Files:
The service requires two pre-trained model files in backend/app/model/:
best_model.pkl: Trained classifier for 25 job categoriestfidf.pkl: Trained TF-IDF vectorizer for text features
NLTK Data:
NLTK data is downloaded to backend/app/model/nltk_data/ at startup backend/server.py660-671:
punkt: Sentence tokenizerstopwords: English stopwords corpus
Sources: backend/pyproject.toml1-40 backend/server.py660-711
Error Handling and Validation
Robust Processing Pipeline
The service implements comprehensive error handling at multiple levels:
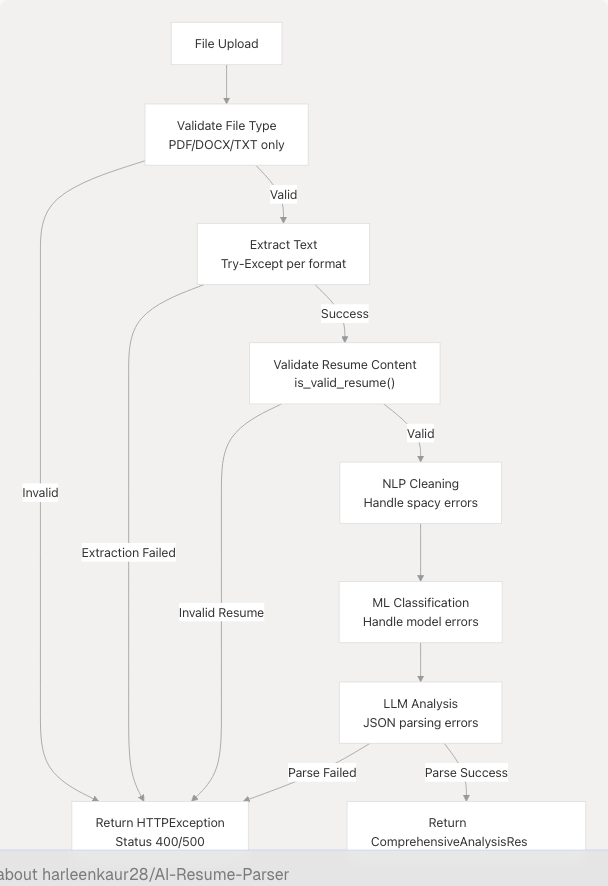
Validation Layers:
- File Type Validation backend/server.py766-786: Rejects unsupported formats
- Content Validation backend/server.py901-921: Checks for resume-specific keywords (Experience, Education, Skills, etc.)
- Extraction Error Handling backend/server.py788-790: Catches and logs file processing exceptions
- LLM API Error Handling backend/server.py880-899: Handles authentication errors, rate limits, and API failures
- JSON Parsing Validation: Ensures LLM output conforms to Pydantic schemas
Resume Validation:
The is_valid_resume() function backend/server.py901-921 checks for at least one of these keywords:
- Experience
- Education
- Skills
- Profile
- Work History
- Projects
- Certifications
LLM Fallback Strategy:
If LLM formatting fails, the service falls back to returning the original text backend/server.py887-898 with appropriate error messaging.
Sources: backend/server.py766-921
Performance Considerations
Optimization Strategies
The service implements several performance optimizations:
| Strategy | Implementation | Benefit |
|---|---|---|
| Model Pre-loading | Load ML models at startup | Avoid repeated disk I/O per request |
| Low LLM Temperature | temperature=0.1 |
Faster inference, more deterministic |
| Minimal Context | Limit resume text to relevant excerpts | Reduce token count, faster LLM calls |
| Cached NLP Models | Spacy model loaded once | Avoid re-initialization overhead |
| Streaming Disabled | Synchronous LLM calls | Simpler error handling |
Processing Time:
Typical resume analysis takes 4-8 seconds:
- Text extraction: <1 second
- NLP cleaning: <1 second
- ML classification: <0.5 seconds
- Field extraction: <0.5 seconds
- LLM comprehensive analysis: 2-5 seconds (network-dependent)
Scalability Considerations:
The service is stateless and can be horizontally scaled. The primary bottleneck is LLM API rate limits (external dependency).
Sources: backend/server.py68-86 backend/server.py702-735
Configuration and Environment Variables
Required Environment Variables
| Variable | Purpose | Default | Required |
|---|---|---|---|
GOOGLE_API_KEY |
Google Gemini API authentication | None | Yes |
DATABASE_URL |
PostgreSQL connection string | None | Yes (for persistence) |
API Key Management:
The service loads environment variables using python-dotenv backend/server.py47-49:
from dotenv import load_dotenv
load_dotenv()
If GOOGLE_API_KEY is not found, LLM functionality is disabled with a warning backend/server.py70-75:
google_api_key = os.getenv("GOOGLE_API_KEY")
if not google_api_key:
print("Warning: GOOGLE_API_KEY not found in .env. LLM functionality will be disabled.")
Sources: backend/server.py47-86
Future Enhancements
Based on the codebase structure, potential enhancements include:
- Async Processing: Convert synchronous LLM calls to async for better concurrency
- Batch Analysis: Support bulk resume processing for recruiters
- Custom Models: Allow fine-tuned classification models per industry
- Multilingual Support: Extend beyond English using multilingual Spacy models
- PDF Form Detection: Handle PDF forms and structured templates better
- Skills Taxonomy: Integrate with standardized skills ontologies (e.g., ESCO, O*NET)
- Version Control: Track resume analysis history and changes over time
Sources: Based on system architecture analysis